Парсер – что это такое простыми словами, как его настроить и пользоваться программой для парсинга сайтов
24 июня 2020 Опубликовано в разделах: Азбука терминов. 86250


Есть приложения, которые позволяют автоматизировать множественные процессы интернет-маркетинга. Они необходимы многим бизнесменам, которые либо хотят использовать сбор информации с конкурирующих веб-источников, либо защитить себя от подобного «воровства» контента. В любом случае, работая с интернет-ресурсом важно знать о парсинге сайта – что это такое (мы расскажем простыми словами) и как настроить и пользоваться парсером данных.
Parsing
Данный механизм действует по заданной программе и сопоставляет определенный набор слов, с тем, что нашлось в интернете. Как поступать с полученной информацией, написано в командной строке, называемой «регулярное выражение». Она состоит из символов и задает правило поиска.
Фактически понятие переводится с английского языка как семантический анализ или разбор. Но термин, применяемый в технологиях создания и наполнения вебсайта, имеет более широкое значение. Это процедура, действие, предполагающее многостороннее исследование страницы, документа, целого раздела на предмет нахождения лексических, грамматических единиц или иных элементов (не только текста, но и видео-, аудио-контента) с последующей систематизацией. Искомые сведения находятся и преобразуются, они подготавливаются для дальнейшей работы с ними. Еще можно сказать, что это быстрая оценка и скорая обработка интернет-ресурса, данных с него. Вручную подобный процесс занял бы много времени, но автоматизация его значительно упрощает.

Таким образом, парсер – это программа для парсинга ключевых слов сайтов. Она настраивается, в нее вводятся параметры поиска и прочие указания, чтобы получить семантическое ядро или анализ карточек товаров для интернет-магазина.
Исходником может быть ваш собственный веб-ресурс (для аналитики и принятия последующих решений), сайт конкурента, страничка из социальных сетей и пр. Полученным результатом можно будет пользоваться в дальнейшем по усмотрению владельца. Приведем понятный пример. По такому принципу работают поисковые системы, когда они анализируют страницы на релевантность, наличие ключевых слов из запроса и соответствие тематике, а затем на основе полученных сведений автоматически формируется выдача.

Законно ли использовать парсинг семантического ядра с сайтов конкурентов
Посмотрим на это с такой стороны. Если ресурс является открытым для пользователей, то вся представленная информация может собираться вручную. А если это доступно, то и применение специального софта для автоматизации процесса не является противозаконной. Опять же при условии, что доступ разрешен всем.

Сквозная аналитика
Это услуга, которая признана дать отчет о результативности интернет-рекламы. То есть с помощью сервиса собираются данные с рекламных площадок, связывает их со сведениями об обращениях и продажах. Анализируя это, можно понять, насколько эффективно было использование того или иного метода продвижения. Таким образом возможно выявить, какие каналы являются затратными, но не приносят достаточно выгодного результата, это помогает оптимизировать бюджет.
Такую услугу постоянной аналитики предлагает компания SEMANTICA в комбинации с комплексным продвижением сайтов. Клиенты этого агентства могут наблюдать за тем, какой результат он получает от того или иного действия, проекта. Все сведения предоставляются в виде отчетов, диаграмм.
Для чего нужен парсинг
Первое с чем сталкивается начинающий руководитель – вокруг много информации, слишком большое ее количество затрудняет возможность оперировать большинством ее массы вручную.
Достоинства применения программ для парсинга каталога товаров с сайта для интернет-магазина
Сравним автоматический режим сбора с ручным, преимущества:
Ограничения: почему бывает сложно парсить
Многие задумываются о том, как защитить сайт от парсинга, потому что не хотят терять уникальность контента. Поэтому используют различные программы, которые запрещают доступ к ресурсу ботам.

Как работает парсинг и какой контент можно парсить своими руками или автоматически
Вам удастся получить любую информацию (текстовую или медийную), которая находится в открытом доступе, например:
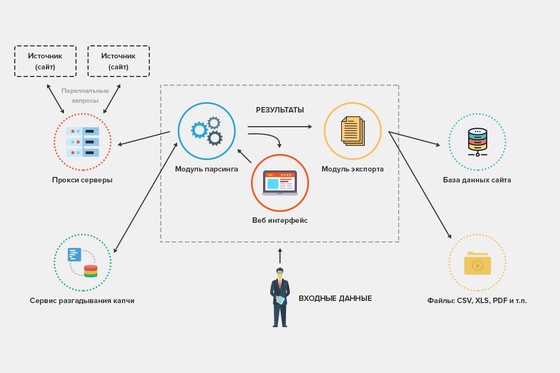
Алгоритм работы парсера
Тонкости процесса зависят от задачи, которая забивается в программы, но в остальном действия имеют следующую последовательность, схему:
Способы применения
Парсинг для начинающих начинается с анализа конкурирующих фирм, чтобы сформировать собственную ценовую политику и план продвижения, стратегию интернет-маркетинга. А уже уверенные пользователи одновременно используют парсеры и для изучения конкурентов, и для аудита своего ресурса, для сравнения полученных сведений. Такая работа в тесной связке помогает поддерживать конкурентоспособность на высоком уровне.

Как парсить данные
Можно пойти двумя путями – купить программу, которых представлено большое множество, или создать приложение собственными силами фактически на любом из языков программирования.
Как спарсить цену
Определение ценовой политики – это самая ходовая задача для приложений. Для этого необходимо посмотреть код анализируемого товара и ввести его в программу. Она автоматически подтянет другие позиции, отвечающие запросу. Сэкономить время и повысить эффективность можно, если ограничить круг страничек. Например, так он не будет искать по разделу с информационными статьями. Добавлять стоит категории и сами карточки продукции. Прописываются ссылки на них в карте XML.
Как парсить характеристики товаров
Для этого понадобится вручную определить код у каждого продукта, который вам требуется. Затем можно подвязать полученные сведения с автозаполнением полей в вашем интернет-магазине. Особенно актуально подтягивать описание, когда вы занимаетесь реализацией техники, автомобилей, смартфонов. Часто характерные особенности берутся на сайтах производителей. Они не могут отличаться уникальностью, поэтому поисковики за это не ругаются.

Как спарсить отзывы (с рендерингом)
Процедура аналогичная – копирование кода, а затем его ввод в приложение для парсинга. Но несколько отличаются последующие действия. Обычно комментарии открываются в тот момент, когда пользователь прокручивает страницу вниз, чтобы ознакомиться с ними. И тогда нужно снова залезть в настройки и изменить поле «Рендеринг» на JavaScript. В таком случае программа будет себя вести точно как юзер, прокручивая вниз контент до отзывов.
Как парсить структуру сайта
Это важное занятие, которым также часто занимаются новички. Основная задача – узнать, из каких разделов, подразделов и категорий состоит веб-ресурс, чтобы сделать аналогичные. Структурирование определяется, благодаря изучению breadcrumbs, или хлебных крошек в буквальном переводе. На самом деле термин подразумевает навигационную цепочку, которая выстраивается от начального элемента (корневого файла) до итогового.

Что нужно для этого сделать:
Теперь вы знаете, как сделать парсинг сайта интернет-магазина самостоятельно. Но не всегда удается правильно распорядиться полученной информацией, а также быстро обойти все существующие ограничения на поиск. В таком случае мы рекомендуем обратиться к компании по продвижению вебсайтов. Специалисты агентства SEMANTICA производят анализ конкурентов на начальном этапе работы с проектом, а заказчик получает готовый результат в удобном формате.
Что такое парсер и как он работает

Чтобы поддерживать информацию на своем ресурсе в актуальном состоянии, наполнять каталог товарами и структурировать контент, необходимо тратить кучу времени и сил. Но есть утилиты, которые позволяют заметно сократить затраты и автоматизировать все процедуры, связанные с поиском материалов и экспортом их в нужном формате. Эта процедура называется парсингом.
Давайте разберемся, что такое парсер и как он работает.
Что такое парсинг?
Начнем с определения. Парсинг – это метод индексирования информации с последующей конвертацией ее в иной формат или даже иной тип данных.
Парсинг позволяет взять файл в одном формате и преобразовать его данные в более удобоваримую форму, которую можно использовать в своих целях. К примеру, у вас может оказаться под рукой HTML-файл. С помощью парсинга информацию в нем можно трансформировать в «голый» текст и сделать понятной для человека. Или конвертировать в JSON и сделать понятной для приложения или скрипта.
Но в нашем случае парсингу подойдет более узкое и точное определение. Назовем этот процесс методом обработки данных на веб-страницах. Он подразумевает анализ текста, вычленение оттуда необходимых материалов и их преобразование в подходящий вид (тот, что можно использовать в соответствии с поставленными целями). Благодаря парсингу можно находить на страницах небольшие клочки полезной информации и в автоматическом режиме их оттуда извлекать, чтобы потом переиспользовать.
Ну а что такое парсер? Из названия понятно, что речь идет об инструменте, выполняющем парсинг. Кажется, этого определения достаточно.
Какие задачи помогает решить парсер?
При желании парсер можно сподобить к поиску и извлечению любой информации с сайта, но есть ряд направлений, в которых такого рода инструменты используются чаще всего:

Серый парсинг
Такой метод сбора информации не всегда допустим. Нет, «черных» и полностью запрещенных техник не существует, но для некоторых целей использование парсеров считается нечестным и неэтичным. Это касается копирования целых страниц и даже сайтов (когда вы парсите данные конкурентов и извлекаете сразу всю информацию с ресурса), а также агрессивного сбора контактов с площадок для размещения отзывов и картографических сервисов.
Но дело не в парсинге как таковом, а в том, как вебмастера распоряжаются добытым контентом. Если вы буквально «украдете» чужой сайт и автоматически сделаете его копию, то у хозяев оригинального ресурса могут возникнуть вопросы, ведь авторское право никто не отменял. За это можно понести реальное наказание.
Добытые с помощью парсинга номера и адреса используют для спам-рассылок и звонков, что попадает под закон о персональных данных.
Где найти парсер?
Добыть утилиту для поиска и преобразования информации с сайтов можно четырьмя путями.
При отсутствии разработчиков в штате я бы советовал именно десктопную программу. Это идеальный баланс между эффективностью и затратами. Но если задачи стоят не слишком сложные, то может хватить и облачного сервиса.
Плюсы парсинга
У автоматического сбора информации куча преимуществ (по сравнению с ручным методом):
Так что нет никакого смысла «парсить» руками, когда можно доверить эту операцию подходящему ПО.
Минусы парсинга
Главный недостаток парсеров заключается в том, что ими не всегда удается воспользоваться. В частности, когда владельцы чужих сайтов запрещают автоматический сбор информации со страниц. Есть сразу несколько методов блокировки доступа со стороны парсеров: и по IP-адресам, и с помощью настроек для поисковых ботов. Все они достаточно эффективно защищают от парсинга.
В минусы метода можно отнести и то, что конкуренты тоже могут использовать его. Чтобы защитить сайт от парсинга, придется прибегнуть к одной из техник:
Но все методы защиты легко обходятся, поэтому, скорее всего, придется с этим явлением мириться.
Алгоритм работы парсера
Парсер работает следующим образом: он анализирует страницу на наличие контента, соответствующего заранее заданным параметрам, а потом извлекает его, превратив в систематизированные данные.
Процесс работы с утилитой для поиска и извлечения найденной информации выглядит так:
Естественно, процедура парсинга через специализированное ПО описана лишь в общих чертах. Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Как пользоваться парсером?
На начальных этапах парсинг пригодится для анализа конкурентов и подбора информации, необходимой для собственного проекта. В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
При работе с парсером весь процесс строится вокруг вводимых параметров для поиска и извлечения контента. В зависимости от того, с какой целью планируется парсинг, будут возникать тонкости в определении вводных. Придется подгонять настройки поиска под конкретную задачу.
Иногда я буду упоминать названия облачных или десктопных парсеров, но использовать именно их необязательно. Краткие инструкции в этом параграфе подойдут практически под любой программный парсер.
Парсинг интернет-магазина
Это наиболее частый сценарий использования утилит для автоматического сбора данных. В этом направлении обычно решаются сразу две задачи:
В первом случае стоит воспользоваться утилитой Marketparser. Указать в ней код продукта и позволить самой собрать необходимую информацию с предложенных сайтов. Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Во втором случае нужно разыскать код товара и указать его в программе-парсере. Упростить задачу помогают специальные приложения. Например, Catalogloader – парсер, специально созданный для автоматического сбора данных о товарах в интернет-магазинах.
Парсинг других частей сайта
Принцип поиска других данных практически не отличается от парсинга цен или адресов. Для начала нужно открыть утилиту для сбора информации, ввести туда код нужных элементов и запустить парсинг.
Разница заключается в первичной настройке. При вводе параметров для поиска надо указать программе, что рендеринг осуществляется с использованием JavaScript. Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Также парсинг используют для сбора данных о структуре сайта. Благодаря элементам breadcrumbs, можно выяснить, как устроены ресурсы конкурентов. Это помогает новичкам при организации информации на собственном проекте.
Обзор лучших парсеров
Далее рассмотрим наиболее популярные и востребованные приложения для сканирования сайтов и извлечения из них необходимых данных.
В виде облачных сервисов
Под облачными парсерами подразумеваются веб-сайты и приложения, в которых пользователь вводит инструкции для поиска определенной информации. Оттуда эти инструкции попадают на сервер к компаниям, предлагающим услуги парсинга. Затем на том же ресурсе отображается найденная информация.
Преимущество этого облака заключается в отсутствии необходимости устанавливать дополнительное программное обеспечение на компьютер. А еще у них зачастую есть API, позволяющее настроить поведение парсера под свои нужды. Но настроек все равно заметно меньше, чем при работе с полноценным приложением-парсером для ПК.
Наиболее популярные облачные парсеры
Похожих сервисов в сети много. Причем как платных, так и бесплатных. Но вышеперечисленные используются чаще остальных.
В виде компьютерных приложений
Есть и десктопные версии. Большая их часть работает только на Windows. То есть для запуска на macOS или Linux придется воспользоваться средствами виртуализации. Либо загрузить виртуальную машину с Windows (актуально в случае с операционной системой Apple), либо установить утилиту в духе Wine (актуально в случае с любым дистрибутивом Linux). Правда, из-за этого для сбора данных потребуется более мощный компьютер.
Наиболее популярные десктопные парсеры
Это наиболее востребованные утилиты для парсинга. У каждого из них есть демо-версия для проверки возможностей до приобретения. Бесплатные решения заметно хуже по качеству и часто уступают даже облачным сервисам.
В виде браузерных расширений
Это самый удобный вариант, но при этом наименее функциональный. Расширения хороши тем, что позволяют начать парсинг прямо из браузера, находясь на странице, откуда надо вытащить данные. Не приходится вводить часть параметров вручную.
Но дополнения к браузерам не имеют таких возможностей, как десктопные приложения. Ввиду отсутствия тех же ресурсов, что могут использовать программы для ПК, расширения не могут собирать такие огромные объемы данных.
Но для быстрого анализа данных и экспорта небольшого количества информации в XML такие дополнения подойдут.
Наиболее популярные расширения-парсеры
Вместо заключения
На этом и закончим статью про парсинг и способы его реализации. Этого должно быть достаточно, чтобы начать работу с парсерами и собрать информацию, необходимую для развития вашего проекта.
Руководство по парсингу веб-сайтов в 2021 году
Меня зовут Максим Кульгин и моя компания xmldatafeed занимается парсингом сайтов в России порядка четырех лет. Ежедневно мы парсим более 500 крупнейших интернет-магазинов в России и на выходе мы отдаем данные в формате Excel/CSV и делаем готовую аналитику для маркетплейсов. Тема парсинга в последнее время становится все более востребованной и в этой статье мы хотим дать общий обзор подходов и механизмов парсинга данных, учитывая правовые особенности.
За последнее десятилетие данные стали ресурсом для развития бизнеса, а Интернет — их основным источником благодаря пяти миллиардам пользователей, формирующим миллиарды фрагментов данных каждую секунду. Анализ данных Всемирной паутины может помочь компаниям выявлять скрытые закономерности, позволяющие им добиваться выполнения своих целей. Однако сбор большого объема данных — непростая для компаний задача, особенно для тех, которые думают, что кнопка «Экспортировать в Excel» (если такая присутствует) и обработка данных вручную — единственные способы сбора данных.
Парсинг веб-сайтов позволяет компаниям автоматизировать процессы сбора данных во Всемирной паутине, используя ботов или автоматические скрипты, называемые «обходчиками» веб-страниц, автоматическими сборщиками данных или веб-сборщиками (web crawlers). В этой статье раскрыты все важные аспекты парсинга веб-сайтов, включая понятие парсинга, почему он важен, как он работает, варианты применения, а также сведения о поставщиках парсеров и руководство по доступным к покупке программным продуктам и услугам.
Парсинг веб-сайтов, который также называют сбором/извлечением данных, скрейпингом данных или содержимого экрана, добычей данных/интернет-данных и иногда обходом/сканированием Всемирной паутины, — это процесс извлечения данных из веб-сайтов.
Процесс парсинга веб-сайтов включает в себя отправку запросов на получение веб-страницы и извлечение из нее машиночитаемой информации.
Всё более широкое использование аналитики данных и автоматизации — существенные тенденции бизнеса. Парсинг веб-сайтов может стать движущей силой для обеих тенденций. Помимо этих причин, у парсинга веб-сайтов есть множество применений, которые могут повлиять на все отрасли. Парсинг веб-сайтов дает компаниям возможность:
Эти факторы объясняют возрастающий интерес к парсингу веб-сайтов, который можно наблюдать в Google Trends на представленном выше изображении.
Обычно процесс парсинга веб-сайтов состоит из следующих последовательных шагов:
Распространенные варианты применения парсинга веб-сайтов перечислены ниже.
Чтобы называться компаний по парсингу веб-сайтов, поставщик подобных программных решений должен предоставлять возможность извлечения данных из множества интернет-ресурсов и возможность экспорта извлеченных данных в различные форматы. Да, сфера парсинга веб-сайтов переполнена, и есть разные способы решения задач по парсингу веб-сайтов на корпоративном уровне.
Фреймворки с открытым исходным кодом делают парсинг веб-сайтов дешевле и проще для личного использования. Наиболее широко используемые инструменты: Scrapy, Selenium, BeautifulSoup и Puppeteer.
Пользователи могут собирать информацию, используя библиотеки наподобие Selenium, чтобы автоматизировать этот процесс. Когда на веб-странице есть список, то чаще всего есть и другие страницы, помимо той, которая сразу отображается пользователю. Пример — веб-страницы с «бесконечной прокруткой». Например, предположим, что вы просматриваете веб-страницы YouTube. На веб-странице, которую вы просматриваете, среди всех перечисленных видео не оказалось такого, который вы бы захотели посмотреть. Затем вам нужно прокрутить список вниз, чтобы появились следующие видео. Selenium позволяет пользователям автоматизировать перемещение по последующим страницам списка и сканирование требуемой информации о каждом элементе списка. Далее пользователи могут сформировать набор данных, содержащий информацию о каждом элементе списка, представленного на веб-сайте. Например, можно создать набор данных о фильмах, в который будут входить наименования, рейтинги IMDb, актеры и позиции фильмов в топе 250 IMDb, сканируя список лучших фильмов по версии IMDb с помощью инструментов с открытым исходным кодом наподобие Scrapy.
Хотя на рынке есть различные проприетарные решения, продукты разделены на два типа:
Хотя парсить данные со своего собственного веб-сайта нетрудно, эта задача будет более сложной на веб-сайтах, стремящихся противодействовать сканированию своего контента роботами, которые не относятся к роботам поисковых систем. Как следствие, передовые парсеры собирают данные с использованием набора различных IP-адресов и цифровых подписей, действуя не как автоматический программный робот, а как группа пользователей, просматривающих веб-сайт.
Полностью управляемые услуги по парсингу веб-сайтов, также называемые «данные-как-услуга» (data-as-a-service, DaaS), будут более удобны для компаний, которым нужен широкомасштабный сбор данных. Работа с веб-сервисами, предоставляющими такие услуги, обычно выглядит так:
Такие компании, как Yipitdata, PromptCloud и ScrapeHero, — некоторые из поставщиков, предлагающих полностью управляемые услуги по парсингу веб-сайтов.
Используя готовое существующее программное обеспечение (ПО) с открытым или закрытым исходным кодом и навыки программирования, любая компания может создавать качественные парсеры веб-сайтов. При условии, что у компании есть технический персонал для осуществления этой задачи, и что парсинг необходим для реализации стратегически важного проекта, собственную разработку можно считать оптимальным вариантом.
Выбор подходящего инструмента или веб-сервиса для сбора данных во Всемирной паутине зависит от различных факторов, включая тип проекта, бюджет и наличие технического персонала. Чтобы кратко охарактеризовать представленную выше схему принятия решения, правильный ход мыслей при выборе автоматического сборщика данных должен быть таким:
Коротко говоря, если: при парсинге собираются общедоступные данные, парсинг не наносит вред компании-владельцу данных, среди собранных данных нет персональных и при повторной публикации собранных данных добавляется ссылка на источник, то, по всей видимости, заниматься парсингом законно. Однако это не юридическое заключение, поэтому, пожалуйста, обратитесь к профессиональному юристу за конкретной консультацией.
Законность парсинга ранее долгое время была неоднозначной, но сейчас в этом вопросе больше ясности. В настоящее время нормативно-правовые акты, регулирующие конфиденциальность персональных данных, наподобие GDPR Европейского союза и CCPA в Калифорнии не препятствуют парсингу веб-сайтов. В России недавно приняли дополнительные поправки в закон об Персональных данных. Просто убедитесь, что:
Говоря о компаниях, Апелляционный суд девятого округа США после иска LinkedIn против hiQ постановил, что автоматический парсинг общедоступных данных, очевидно, не нарушает Закон о компьютерном мошенничестве и злоупотреблении (Computer Fraud and Abuse Act, CFAA).
Тем не менее при использовании парсинга веб-сайтов действуют ограничения.
При оценке законности парсинга учтите также, что каждый результат поиска, который вы видите на страницах поисковых систем, был собран ею. Помимо этого, сообщается, что хедж-фонды тратят миллиарды на сбор данных, чтобы принимать более эффективные инвестиционные решения. Поэтому парсинг — это не сомнительная практика, которую применяют только небольшие компании.
Почему владельцы веб-сайтов хотят защитить их от парсинга?
Отчет 2020 от imperva о нежелательных программных роботах, собирающих данные
Распространенные и наиболее успешные приемы парсинга веб-сайтов:
Многие администраторы крупных веб-сайтов применяют инструменты для защиты от роботов. Роботам приходится обходить их, чтобы просканировать большое количество HTML-страниц. Использование прокси-серверов и отправка запросов через разные IP-адреса могут помочь преодолеть эти трудности.
Переход от статического IP-адреса на динамический также может оказаться полезным для того, чтобы парсер не обнаружили и не заблокировали.
Следует ограничить частоту отправки запросов на один и тот же веб-сайт по двум причинам:
Согласно GDPR, незаконно собирать личную информацию (personally identifiable information, PII) резидентов ЕС, если только у вас нет их явного на это согласия.
Если вы собираетесь собирать данные на веб-сайте, где требуется проходить авторизацию, вам нужно принять пользовательское соглашение (Terms & Conditions), чтобы зарегистрироваться там. Некоторые пользовательские соглашения включают в себя принципы компаний, связанные с парсингом данных, в соответствии с которыми вам не разрешается парсить любые данные на веб-сайте.
Однако даже несмотря на то, что пользовательское соглашение LinkedIn однозначно запрещает парсинг данных, как упоминалось выше, парсинг LinkedIn пока еще не нарушает закон. Мы не дает юридическое заключение и не беремся однозначно разъяснять смысл пользовательских соглашений компаний.
Парсинг превращается в игру в кошки-мышки между владельцами контента и его сборщиками — обе стороны тратят миллиарды на преодоление мер, разработанных другой стороной. Можно ожидать, что обе стороны будут использовать машинное обучение для создания более продвинутых систем.
Открытый исходный код играет важную роль в разработке ПО, в том числе в области разработки парсеров. Кроме того, популярность Python растет, и она уже довольно высока. Можно ожидать, что библиотеки с открытым исходным кодом, как например: Selenium, Scrapy и Beautiful Soup, которые работают на Python, будут в ближайшем будущем формировать подходы к парсингу веб-сайтов.
Вместе с библиотеками с открытым исходным кодом интерес к искусственному интеллекту (ИИ) делает будущее более радужным, поскольку системы на основе ИИ в значительной степени полагаются на данные, а автоматизация сбора данных может содействовать различным вариантам применения ИИ с тренировкой на общедоступных данных.



